Task-driven Webpage Saliency
European Conference on Computer Vision (ECCV) 2018Quanlong Zheng Jianbo Jiao Ying Cao Rynson W.H. Lau

Abstract
In this paper, we present an end-to-end learning framework for predicting task-driven visual saliency on webpages. Given a webpage, we propose a convolutional neural network to predict where people look at it under different task conditions. Inspired by the observation that given a specific task, human attention is strongly correlated with certain semantic components on a webpage (e.g., images, buttons and input boxes), our network explicitly disentangles saliency prediction into two independent sub-tasks: task-specific attention shift prediction and taskfree saliency prediction. The task-specific branch estimates task-driven attention shift over a webpage from its semantic components, while the task-free branch infers visual saliency induced by visual features of the webpage. The outputs of the two branches are combined to produce the final prediction. Such a task decomposition framework allows us to efficiently learn our model from a small-scale task-driven saliency dataset with sparse labels (captured under a single task condition). Experimental results show that our method outperforms the baselines and prior works, achieving state-of-the-art performance on a newly collected benchmark dataset for task-driven webpage saliency detection.Network Architecture
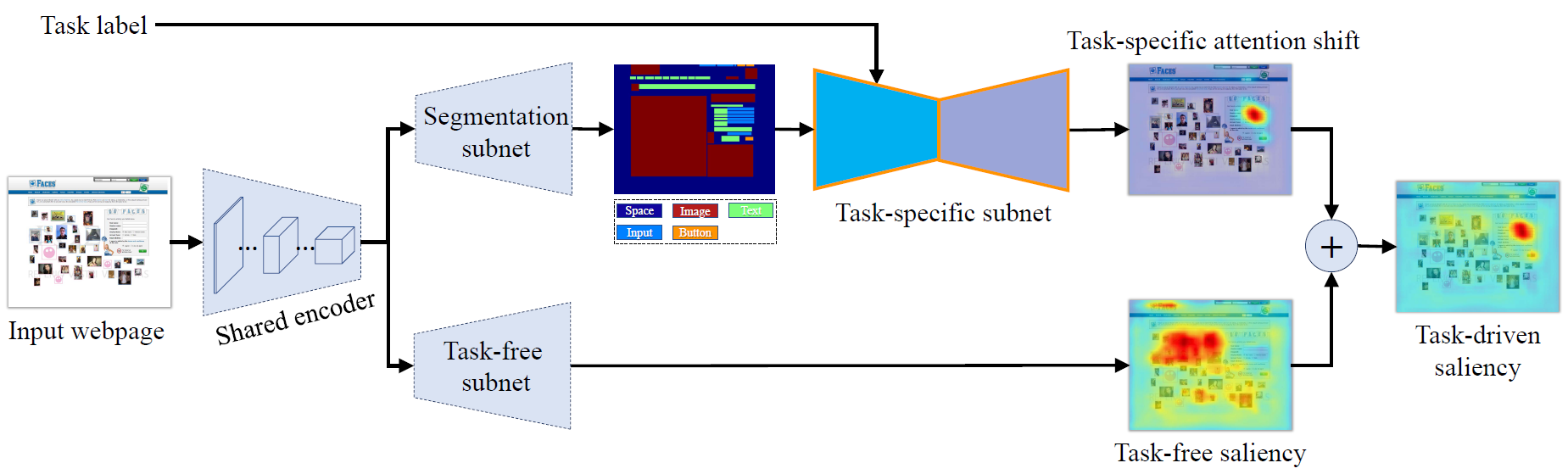
Inputs to our model are a webpage image and a task label (e.g., Signing-up"). The webpage image is first fed to a shared encoder to extract high-level features, which are used by two subnets for predicting task-specific human attention bias and task-free visual saliency. The task-specific subnet takes as input the task label along with a semantic segmentation map from a segmentation subnet, and predicts the task-dependent attention shift (upper), while the task-free subnet predicts the task-independent saliency (lower). The task-specific attention shift and task-free saliency are combined to obtain the final saliency map under the input task.
Downloads
| [Paper] | [Supplementary Material] | [Code] | [Data] |
BibTex
@proceedings{Zheng2018,
author = {Q. Zheng and J. Jiao and Y. Cao and R. Lau},
title = {Task-driven Webpage Saliency},
journal = {ECCV},
year = {2018}
}